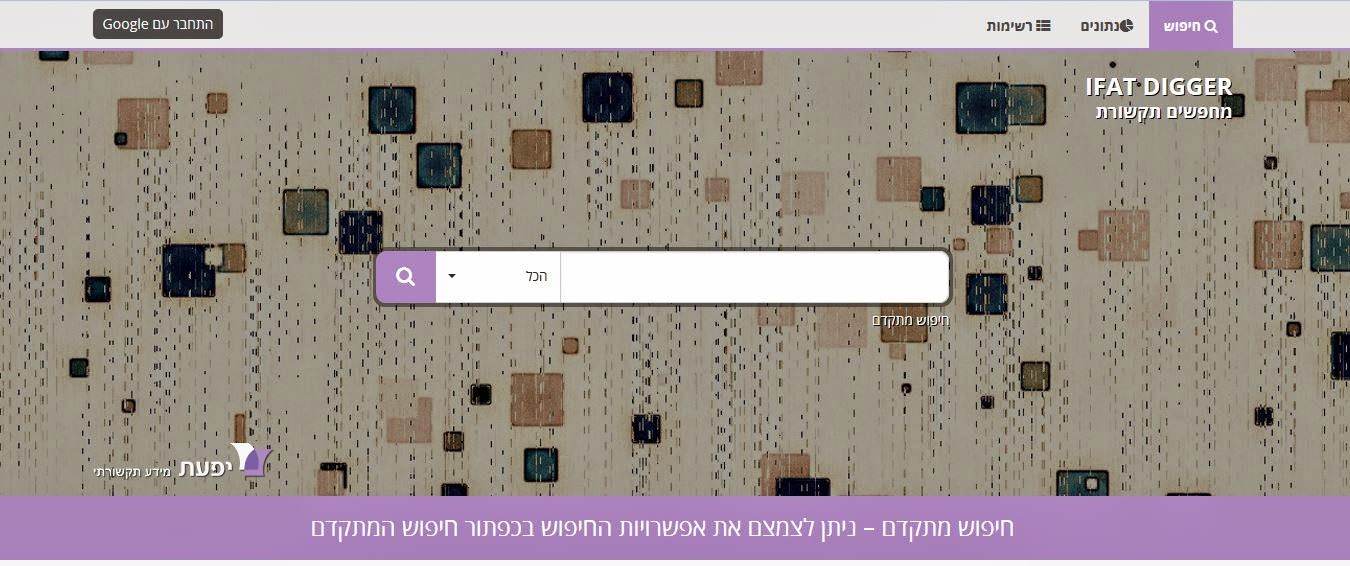
אמש (12 בינואר 2015) הושקה בספריית מדעי החברה
וניהול של אוניברסיטת תל אביב מערכת IFAT DIGGER , מערכת
מידע חדשנית לחיפוש מידע מאוחד בכל העיתונות הישראלית ואמצעי התקשורת בישראל
מאז שנת 2006. מדובר על מאגר מידע כוללני
לאיחזור מידע מתוך אמצעי התקשורת והעיתונות הישראלית מאז שנת 2006 .
הנה תיאור קצר
של המערכת אשר רשמתי וסיכמתי במהלך ההשקה
המעניינת והמרשימה שנערכה בשיתוף בין חברת יפעת תקשורת והנהלת הספרייה למדעי החברה
וניהול באוניברסיטת תל אביב .
קצת על חברת יפעת תקשורת
חברת יפעת תקשורת
פועלת כבר 32 בישראל כחברה מובילה בתחום ניטור התקשורת והעיתונות הישראלית וגם
באמצעות שרותי הפצת המידע המהירים שלה אשר אין להם כיום תחליף בשוק הישראלי. חברת יפעת תקשורת מנטרת את כל העיתונות הישראלית
( לרבות 300 אתרי אינטרנט וגם כל תחנות הרדיו והטלביזיה) ומאפשרת ללקוחות לקבל את הכתבות בזמן אמיתי עפ"י מילות מפתח.
עפ"י דברי
מנכ"ל החברה , מר מני אברהמי, נוצר
בישראל עתה צורך במאגר איחזור מידע מקיף
של כל העיתונות והתקשורת הישראלית בדומה לפורטל האיחזור של חברת Lexis-Nexis בארה"ב ובעולם .
במשך השנים היו הרבה
מאד פניות לחברת יפעת תקשורת מצד סטודנטים וחוקרים לגבי אפשרות של
חיפוש מאוחד בכל רובדי העיתונות הישראלית
והתקשורת "בקליק אחד".
חברת יפעת תקשורת נענתה לאתגר המקצועי והחלה
לפתח מערכת איחזור מידע מתקדמת המאחדת את החיפוש בכל העיתונים ואמצעי התקשורת
בישראל.
התשתית של הנתונים על
כתבות בעיתונות הישראלית בחברת יפעת קיימת
אצלם כבר שנים, ולכן ניתן היה ליישם הלכה למעשה הקמת של מערכת איחזור מידע מאוחדת
של כל העיתונות הישראלית ואמצעי התקשורת.
פיתוח ואיפיון
המערכת
במשך שנתיים נערך
מחקר איפיון מקדים ע"י צוות חברת יפעת תקשורת בקרב חוקרים , ספריות , מרכזי
מידע, מידענים וסטודנטים . בתהליך האיפיון נטלה חלק מרכזי הספרייה למדעי החברה
והניהול באוניברסיטת תל אביב בניצוחה של הגב' שלומית פרי , מנהלת הספרייה ובשיתוף
המידעניות בספרייה .
אוכלוסיית היעד
מערכת "דיגר" נועדה בראש ובראשונה לתת
מענה מחקרי לסטודנטים, חוקרים וספריות אקדמאיות בישראל הזקוקים למאגר נתונים מאוחד
על העיתונות הישראלית ואמצעי התקשורת. בעקרון,
מערכת "דיגר" תפעל בעתיד
הקרוב כמאגר מידע מקוון בספריות ובמכוני
המחקר בישראל . הספריות או מכוני המחקר יחוייבו
מבחינת התשלום במנוי שנתי .
מערכת
"דיגר" כוללת את המודולים הבאים :
- מודול החיפוש ( איחזור מידע)
- מודול נתונים
- מודול רשימות ( צבירת פריטי מידע) .
מערכת איחזור
המידע "דיגר" של חברת יפעת מאפשרת חיפוש טקסטואלי כולל ומקיף על המידע שהתפרסם משנת
2006 ועד היום בעיתונות היומית, אתרי אינטרנט ובתוכניות האקטואליה ברדיו
ובטלביזיה.
באופן מעשי , מערכת
"דיגר" מחפשת על הטקסט המלא של כל העיתונים ואמצעי התקשורת הישראליים ,
אך מציגה את התוצאות רק של אותם קטעי המידע העונים על החיפוש ולא את
כל הכתבה עצמה (full text). כלומר, המשתמשים רואים רק את סביבת האיחזור (
מופעי המילים וקטעי המאמר ).
התוצאות במערכת
החיפוש מציגות רשימת כותרות , מידע אודות מקור הכתבה והצצה לחלק מהכתבה ( ITEM
) .
החיפוש במערכת הוא
מורפולוגי מלא ( מרכאות, כוכבית ) . ניתן
לחפש צמדי מילים וניתן לצבור את פריטי המידע ברשימות צבירה אישיות.
המערכת מאפשרת , כאמור , גם השוואה של כמה מושגים/מופעים , לדוגמא , השוואה בין מופעי
החשיפה (איזכורים בעיתונות) של ראש הממשלה
נתניהו מול מופעי החשיפה של ראש מפלגת
העבודה הרצוג , גם בהשוואה בו-זמנית לאיזכורים של
ח"כ ציפי לבני.

מדוע מוצגים רק
הקטעים הקצרים בכתבה ובהם ביטויי החיפוש ?
התצוגה של סביבת
הביטויים בלבד בטקסטים הקצרים קשורה
לעובדה כי זכויות היוצרים של כל הכתבות והמאמרים בעיתונות שייכים במלואם לעיתונים
ולאמצעי התקשורת ולא בהכרח לחברת יפעת תקשורת . עם זאת, בשלב מאוחר יותר של המיזם חברת יפעת תקשורת
תציע גם שירות של אספקת המאמרים המלאים עפ"י הזמנה של הסטודנטים או
החוקרים.
מיון וסינון ממצאי החיפוש
ניתן לפלח ולמיין
את תוצאות החיפוש עפ"י :
- המקור
- מדיה
- קהל היעד
- שפה
ניתן לסנן את
החיפוש ל:
- הכל
- שבוע אחרון
- חודש אחרון
- שנה אחרונה
מערכת
"דיגר" כוללת גם מנגנון יעיל של חיפוש מתקדם , כלומר חיפוש ממוקד
יותר עפ"י תאריכים , סוגי מדיה ונושאים .
המערכת המתוקשבת DIGGER מבצעת גם השלמה אוטומאטית של ביטויי החיפוש תוך כדי החיפוש עצמו.
המערכת המתוקשבת
מאפשרת גם הצגת החיפושים האחרונים בDIGGER .

נתונים
מערכת
"דיגר" של חברת יפעת מאפשרת
לקבל את תוצאות החיפוש בצורה של דו"ח כמותי. הדו"ח מציג את אופן הסיקור
המאורגן על פי פילוחים של מקורות : שנים , חודשים . ניתן , כאמור , להשוות עד 4
מושגים/מופעים בתקשורת הישראלית במקביל ולהציגם בדו"ח מרוכז.
רשימות
לאחר קבלת תוצאות
החיפוש , המערכת מאפשרת למשתמש לבחור מהרשימה את הכותרות הרצויות ולהוסיף אותן
לרשימות מצטברות שלו עפ"י נושאים. ניתן להוסיף ולצבור את כותרות החדשות
לרשימות חדשות או קיימות. את הרשימות ניתן לייצא לפורמטים שונים או לשמור בחשבון
הגוגל האישי .